 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
![]() Durch ein aktuelles Projekt, beschäftige ich mich intensiver mit Apache HBase, was eine hervorragenden Gelegenheit bietet meinem Blog mal wieder etwas Leben einzuhauchen…
Durch ein aktuelles Projekt, beschäftige ich mich intensiver mit Apache HBase, was eine hervorragenden Gelegenheit bietet meinem Blog mal wieder etwas Leben einzuhauchen…
Was ist Apache HBase
Wir leben in einem Zeitalter, indem wir alle über das Internet verbunden sind und die Erwartungshaltung haben, dass Informationen (die wir suchen) überall und sofort zur Verfügung stehen.
Aus diesem Grund haben sich Unternehmen darauf spezialisiert, uns zielgerichtet mit Informationen beliefern zu können.
Plattformen wie Hadoop bzw. HDInsight stellen dafür nötige Softwarebasis zur Verfügung.
Wer sich allerdings schon mal mit Hadoop bzw. HDInsight auseinandergesetzt hat, kennt das eher Batch-lastige Verhalten dieser Plattform.
Auch bei den klassischen Datenbanksystemen hat sich in den letzten Jahren einiges getan, um diesen neuen Anforderungen gerecht werden zu können.
Unter anderem kamen neue Ansätze auf, wie beispielsweise die Spaltenbasierte Datenspeicherung oder auch Daten "In-Memory" zu halten.
Ein Grund für die spaltenbasierte Datenspeicherung, ist die Annahme, dass man für eine bestimmte Anfrage nicht alle Werte benötigen wird. Somit würde man I/O Zugriffe reduzieren.
HBase ist zwar keine spalten-orientierte Datenbank, setzt aber unter der Haube die spaltenbasierte Datenspeicherung ein.
Doch zurück zur eigentlichen Frage…
Was ist eigentlich HBase?
HBase ist eine Abkürzung für „Hadoop Database“ und ist eine Open-Source-NoSQL-Datenbank, die wahlfreien Zugriff und starke Konsistenz für große Mengen unstrukturierter bzw. semistrukturierter Daten bietet.
Sie wurde nach dem Vorbild von Googles BigTable Datenbanksystem erstellt.
HBase ist eine schemalose Datenbank in dem Sinne, dass weder die Spalten, noch die Datentypen der in ihnen gespeicherten Daten, vor der Verwendung definiert werden müssen.
Sie skaliert linear, um Petabytes von Daten auf Tausenden Knoten zu behandeln.
Sie nutzt Datenredundanz, Stapelverarbeitung und andere Funktionen, die vom Hadoop-Ökosystem zur Verfügung gestellt werden.
Anlegen eines HDInsight HBase Clusters
Ähnlich zum "normalen" Azure HDInsight, kann auch HBase ganz einfach über das Management Portal angelegt werden.
Hierzu gibt es eignen eigenen Quick-Create Menüpunkt, …
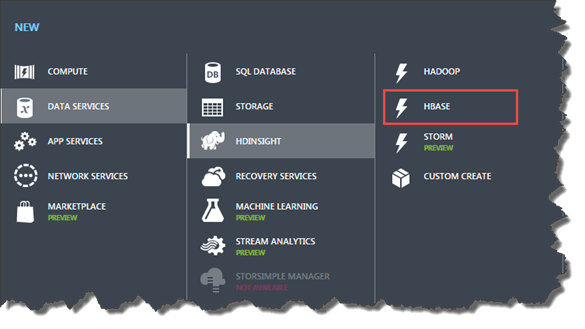
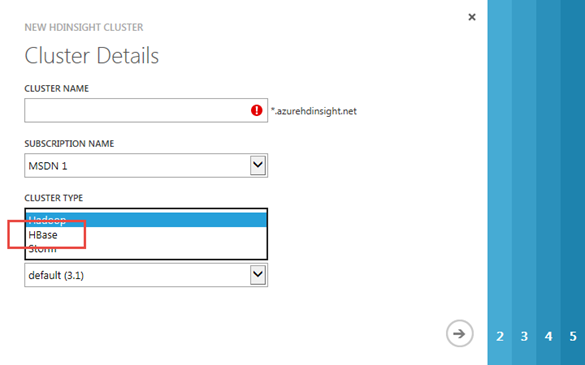
… wie auch die Option in dem HDInsight Assistenten.
Verwendung in .NET Projekten
Um HBase in .NET Projekten verwenden zu können, gibt es auch hier mal wieder ein passendes NuGet Paket:
PM> Install-Package Microsoft.HBase.Client
HBase verwendet zur Datenserialisierung das (von Google entwickelte) Protocol Buffers-Format.
Deshalb wird das NuGet-Paket protobuf-net gleich mitinstalliert.
Das zentrale Element, um mit dem HBase-Cluster kommunizieren zu können, ist die HBaseClient-Klasse
Ein Objekt dieser Klasse ist schnell erstellt:
Anlegen einer Tabelle
Anschließend ist das Anlegen einer Tabelle mit wenigen Zeilen Code realisierbar:
Speichern von Daten
Das Speichern von Daten möchte ich an dieser einfachen Personen-Klasse demonstrieren:
Außerdem habe ich eine Hilfmethode angelegt, welche mir ein Person-Objekt, dem dem CellSet-Objekt des Protocol Buffers, hinzufügt:
Wichtig hierbei ist die key-Eigenschaft des CellSet.Row-Objektes, nachder ich später meine Daten abfragen werde.
Anschließend füge ich der Tabelle ein paar Daten hinzu:
Lesen von Daten
Zum Lesen der Daten habe ich verschiedene Optionen…
Ich kann ich einen ganzen Bereich an Daten mit einem Scanner-Objekt abfragen:
Oder mir einen einzelnen Datensätze mit der GetCells-Methode rauspicken:
Alle in diesem Blog-Post gezeigten Methodenaufrufe der HBaseClient-Klasse gibt es auch als Async.

