 Sascha Dittmann Über .NET, SQL Server und die Cloud
Sascha Dittmann Über .NET, SQL Server und die Cloud
 Im ersten Teil dieser Blog Post Serie habe ich mich mit den Web Rollen in der Windows Azure Plattform beschäftigt.
Im ersten Teil dieser Blog Post Serie habe ich mich mit den Web Rollen in der Windows Azure Plattform beschäftigt.
In diesem Teil wird die bisherige Beispielapplikation mit einer Repository- sowie einer Kontext-Klasse für den Windows Azure Table Storage erweitert. Außerdem werden kleinere Anpassungen an den Datenmodellklassen durchgeführt, um die Arbeit mit den Objekten zu vereinfachen.
Was ist der Table Storage
Der Table Storage ist, aus meiner Sicht, die NoSQL Antwort von Microsoft für die Windows Azure Plattform. Man kann den Table Storage als ein sehr einfaches Objektdatenbanksystem sehen.
Im Original heißt es, dass flexible Entitäten bzw. schemalose Entitäten im Table Storage gespeichert werden können. Genauer gesagt, werden Name-Wert-Paare für jeden einfachen Datentyp, wie z.B. String, Integer, DateTime, Guid, etc., der zu Grunde liegenden Klasse, gespeichert.
Die zu speicherenden Entitäten müssen mindestens folgende drei Eigenschaften enthalten:
-
PartitionKey (Typ: String, Max. Größe: 1 KB)
Der PartitionKey dient zum separieren der Entitäten auf mehrere Server innerhalb des Table Storage Dienstes. (dazu später mehr). -
RowKey (Typ: String, Max. Größe: 1 KB)
Der RowKey muss einen eindeutigen Wert innerhalb einer Partition enthalten und stellt, mit dem PartitionKey, einen zusammengesetzten Primärschlüssel für eine Entität dar. -
Timestamp (Typ: DateTime)
Der Timestamp wird vom Table Storage verwaltet und enthält den Zeitpunkt der letzten Speicherung.
Hinweis:
Die Zeichen /, , # und ? sind als Werte für den RowKey oder PartitionKey unzulässig.
Für die Nutzung des Table Storage, muss als Erstes ein Storage Account angelegt werden (dazu später mehr).
Danach können beliebig viele Tabellen angelegt werden.
Folgende Einschränkungen gibt es für Tabellen im Table Storage:
- Jede Tabelle innerhalb eines Storage Accounts muss einen eindeutigen Namen haben.
- Tabellenamen dürfen nur alphanumerische Zeichen enthalten.
- Tabellenamen dürfen nicht mit einem numerische Zeichen anfangen.
- Bei Tabellenamen wird die Groß-/Kleinschreibung nicht beachtet.
- Tabellenamen müssen mindestens 3, maximal 63 Zeichen lang sein.
-
Maximal können 100 TB Daten pro Storage Account gespeichert werden.
Der Speicherplatz wird gemeinsam für Tabellen, Blob's und Warteschlangen (Queues) genutzt. -
Maximal können 255 Name-Wert-Paare pro Entität gespeichert werden.
Durch die 3 Pflichteigenschaften, bleiben somit 252 benutzerdefinierte Eigenschaften zu freien Verfügung.
Die PartitionKey Eigenschaft
Mit der PartitionKey Eigenschaft einer Datenmodellklasse, werden Entitäten einer Tabelle auf verschiedene Server des Table Storage Dienstes aufgeteilt. Dies dient zur besseren Skalierbarkeit des Table Storages. Allerdings hat man keine Kontrolle darüber, wie dies innerhalb der Windows Azure Plattform geschieht.

Man muss sich bereits beim Entwurf der Applikation Gedanken darüber machen, wie eine Partitionierung der Tabellen aussehen könnte.
Faustregel:
Man sollte die Partitionen anhand der gemeinsam abzufragenden Entitäten festlegen.
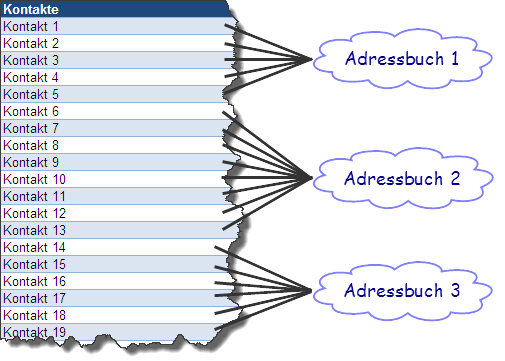
Bei der Blog Post Serien Beispielapplikation habe ich die Adressbücher anhand der Benutzer ID partitioniert (vorerst noch hart verdrahtet), sowie die Kontakte anhand der Adressbuch ID.
Das Storage Account
Um Tabellen im Table Storage anlegen zu können, benötigt man als erstes einen Storage Account.
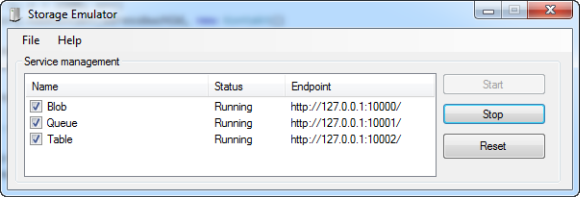
Während der Softwareentwicklung, kann der Storage Emulator, der mit der Windows Azure SDK installiert wurde, genutzt werden.
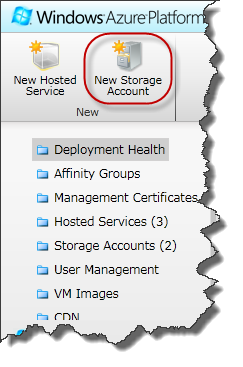
In der Windows Azure Plattform muss dieses Storage Account über das Portal angelegt werden.
Nachdem man sich am Portal angemeldet hat, kann man über das Icon "New Storage Account" (oben links) ein neues Account anlegen
Im Dialog muss dann ein Name (nur Kleinschreibung erlaubt), sowie eine Region oder Affinity Group angegeben werden.
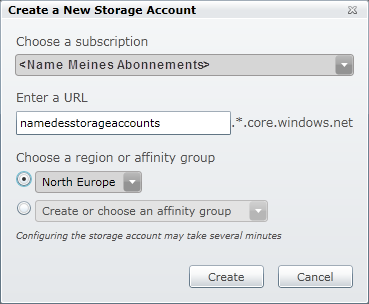
Eine Affinity Group ist eine vom Benutzer vordefinierte, benannte Region, in der sicher gestellt wird, dass Dienste in benachbarten Netzwerksegmenten angelegt werden. Dies soll eine schnelle Kommunikation zwischen den Diensten, die innerhalb einer Applikation verwendet werden, gewährleisten.
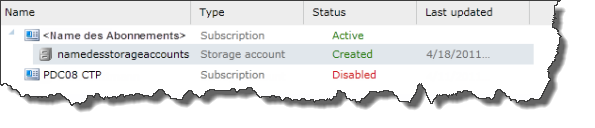
Nach kurzer Wartezeit, erscheint das neu angelegte Storage Account in der Liste.
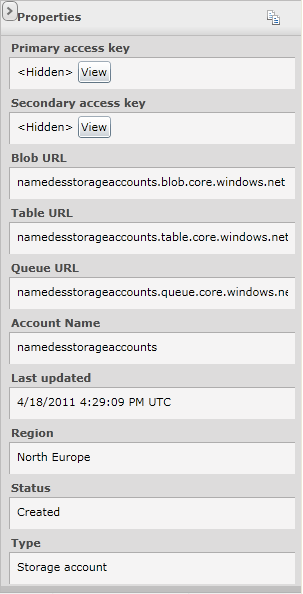
Das Properties Panel (rechts) enthält Detailinformationen, wie z.B. die URL's für den Speicherplatzzugriff.
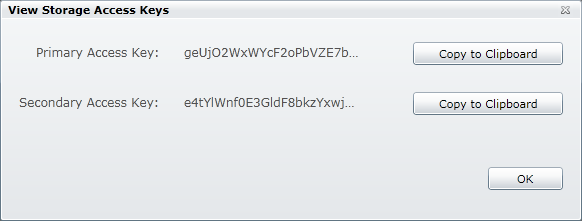
Mit einem Klick auf den View Button beim Primary oder Secondary Access Key, öffnet sich ein weiterer Dialog, in dem man die Speicherzugriffsschlüssel in den Zwischenspeicher kopieren kann.
Änderungen am Beispielprojekt
Nach dieser kleinen Übersicht der Grundzüge des Table Storages, auf zur Beispielapplikation…
Neue Referenzen
Um auf den Table Storage zugreifen zu können, benötigt das "Adressverwaltung.Data" Projekt zwei weitere Referenzen:
- Microsoft.WindowsAzure.StorageClient
- System.Data.Services.Client
Änderungen an den Datenmodellklassen
In den Datenmodellklassen der Beispielapplikation, habe ich kleinere Änderungen durchgeführt, damit sich diese problemlos im Table Storage speichern lassen.
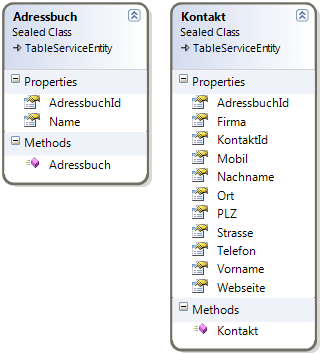
Beide Klassen erben, von der abstrakten Klasse TableServiceEntity, die oben genannten Pflichteigenschaften RowKey, PartitionKey und Timestamp. Diese hätte man auch manuell hinzufügen können.
In den Konstruktoren der Klassen, wird der RowKey mit einer – neu generierten und in einen String umgewandelten – Guid bestückt.
Bei den Eigenschaften AdressbuchId und KontaktId wurde der Setter entfernt und der Getter wandelt den RowKey wieder in eine Guid um und gibt diese zurück.
Die Kontextklasse
Als nächstes habe ich eine Kontextklasse für das Datenmodell angelegt.
Diese leitet von der TableServiceContext Klasse ab und implementiert Eigenschaften zur Abfrage der Datenmodellklassen, sowie Add Methoden, der Datenmodellklassen.

Hinweis:
Mit Hilfe der WritingEntity und ReadingEntity Ereignisse, aus der TableServiceContext Klasse, lassen sich die Speicher- und Lesevorgänge anpassen. So können zum Beispiel einzelne Eigenschaften der Datenmodellklassen ignoriert bzw. ausgeschlossen werden.
Einen Konfigurationseintrag für die Web Rolle hinzufügen
Die Konfiguration der Windows Azure Rollen unterscheidet sich von dem, was man bisher verwendet hat.
Zum Beispiel gibt es weiterhin die web.config Datei in den Projektvorlagen für Web Rollen.
Wenn aber diese Web Rollen in der Windows Azure Plattform installiert wurden, und daraufhin mehreren Instanzen gestartet werden, kann diese nicht mehr als zentraler Ort für die Konfiguration der Applikation genutzt werden.
Hier kommt die ServiceConfiguration.csdef aus dem Windows Azure Projekt in Spiel.
Diese kann auch noch nach der Installation, innerhalb des Windows Azure Portals, editiert werden.
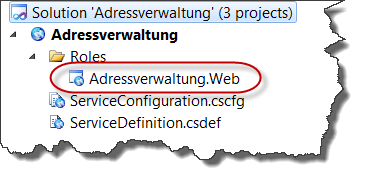
Für das einfache Ändern der Rollenkonfiguration, gibt es in Visual Studio 2010 einen Konfigurationsdialog.
Um in den Konfigurationsdialog zu gelangen, muss man einen Doppelklick auf die entsprechende Rolle im Verzeichnis Roles des Windows Azure Projekts machen:
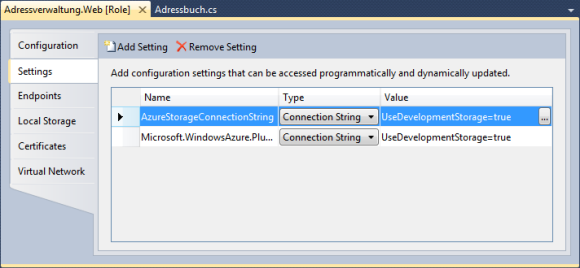
Anschließend wechselt man auf das Settings Tab.
Dort sieht man eine Liste der Konfigurationseinstellungen. Standardmäßig ist hier der Connection String für das Windows Azure Diagnostics Plug-In voreingestellt.
Mit dem Add Settings Button kann man eine weitere Zeile hinzufügen.
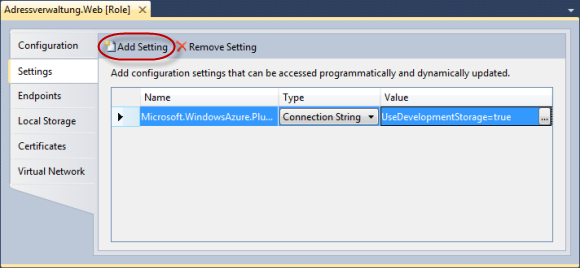
Für die Beispielapplikation habe ich einen weiteren Connection String mit dem Namen AzureStorageConnectionString hinzugefügt.
Mit dem "…" Button öffnet sich der Dialog für die Connection String Konfiguration:
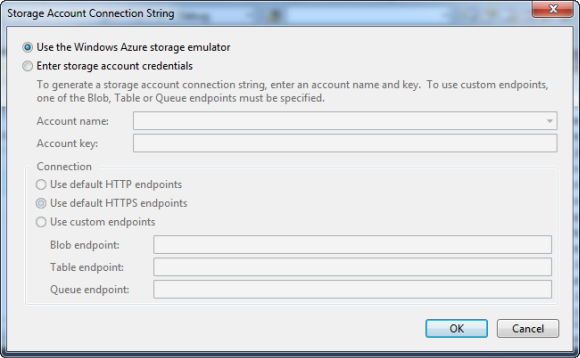
Da ich vorerst den Windows Azure Storage Emulator verwenden werde, konnte ich diesen Dialog, mit einem Klick auf den OK Button, wieder schließen.
Der Konfigurationseintrag innerhalb der Web Rolle
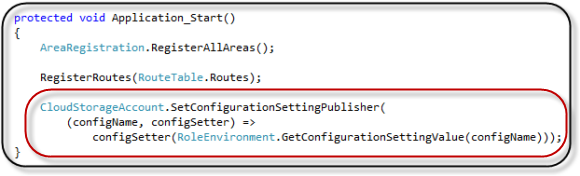
Um den Konfigurationseintrag für das Storage Account verwendet zu können, muss als erstes ein Setting Publisher hinzugefügt werden.
Dies kann man in den Web Rollen am Besten in der Global.asax im der Application_Start Methode unterbringen.
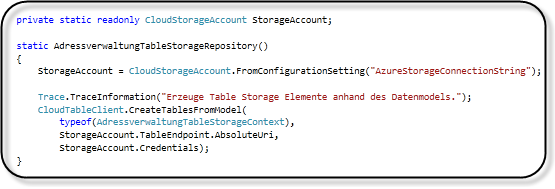
Anschließend kann man diesen, wie z.B. im statischen Konstruktor der Repository Klasse, nutzen, um ein Storage Account Objekt zu erzeugen.
Mit Hilfe der statischen Methode CreateTablesFromModel der CloudTableClient Klasse, können die Tabellen auf Basis der Kontextklasse erzeugt werden.
Die Table Storage Repository Klasse
Neben dem, im vorherigen Abschnitt erwähnten, statischen Konstruktor, möchte ich noch ein paar weitere "Highlights" des Table Storage Repository Klasse aufzeigen:
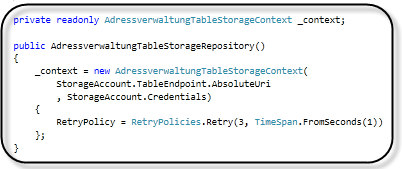
Der Standard Konstruktor erzeugt ein Objekt des Table Storage Kontext.
Hier wird bereits die Retry Policy auf 3 Versuche, in einem Abstand von 1 Sekunde, festgelegt.
Falls bei einer Anfrage des Table Storage Dienstes, nicht rechtzeitigt oder gar nicht geantwortet wird, wird diese Policy für Wiederholungen verwendet.
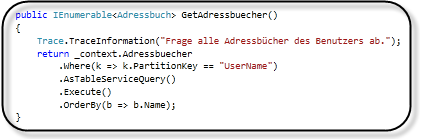
Mit LINQ können die Entitäten abgefragt werden.
Hier gibt es allerdings ein paar Besonderheiten:
-
Bei einer normalen LINQ Abfrage werden maximal 1.000 Entitäten zurückgeliefert.
Wenn allerdings alle Entitäten zurückgeliefert werden sollen, kann die Abfrage mittels AsTableServiceQuery in ein CloudTableQuery Objekt umgewandelt werden.
Anschließend verwendet man die Execute oder BeginExecuteSegmented Methode, um eine Kette von Abfragen auszuführen, die alle Entitäten zurückliefert. -
Gängige Operationen, wie z.B. OrderBy, GroupBy, Join, Count, etc. werden vom Table Storage Dienst nicht unterstützt.
Dies kann aber im Anschluss an eine ausgeführten Abfrage, wie z.B. mittels ToList oder Execute, im Arbeitsspeicher nachgeholt werden.
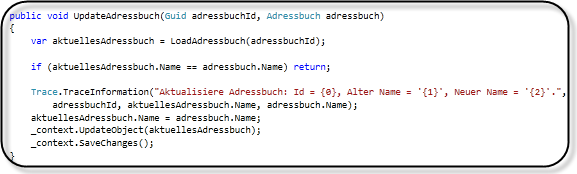
Das hinzufügen, aktualisieren oder löschen von Entitäten ist wiederum ähnlich, wie in anderen Diensten:

Speicherzugriffstransaktionen
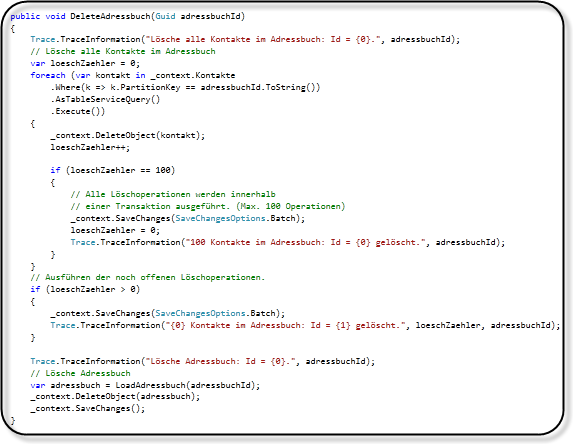
Beim der Löschmethode der Adressbücher möchte ich noch auf eine weitere Besonderheit des Table Storages hinweisen: Die Speicherzugriffstransaktionen.
Jeder Zugriff auf den Table Storage kostet derzeit Geld und benötigt Zeit.
Um dies ein wenig effizienter zu gestallten, können diese Zugriffe in eine Transaktion zusammengefasst werden. Hierzu verwendet man beim der SaveChanges Methode die Option SaveChangesOptions.Batch.
Auch hier gibt es ein paar Einschränkungen:
- Maximal 4 MB Payload pro Batchanfrage
- Maximal 100 Operationen pro Batchanfrage
- Das selbe Objekt darf nicht mehrfach geändert werden
- Die Änderungen müssen in der selben Partition statt finden
Hier das Beispiel aus der Löschmethode der Adressbücher:
Kommende Themen
In den kommenden Blog Posts wird die Beispielanwendung u.a. mit einer Worker Role für die Bildverarbeitung erweitert. Des weiteren wird es Blog Posts zu Themen, wie z.B. Installation, einem SQL Azure Repository, dem Access Control Service und dem Windows Azure Content Distribution Network (CDN) geben.

|
Download der Beispielanwendung: ErsteSchritteMitWindowsAzure02.zip (275 kb) |
